A Python package & command-line tool to gather text on the Web#



Description#
Trafilatura is a Python package and command-line tool designed to gather text on the Web. It includes discovery, extraction and text processing components. Its main applications are web crawling, downloads, scraping, and extraction of main texts, metadata and comments. It aims at staying handy and modular: no database is required, the output can be converted to commonly used formats.
Going from raw HTML to essential parts can alleviate many problems related to text quality, by avoiding the noise caused by recurring elements like headers and footers and by making sense of the data and metadata with selected information. The extractor strikes a balance between limiting noise (precision) and including all valid parts (recall). It is robust and reasonably fast.
Trafilatura is widely used and integrated into thousands of projects by companies like HuggingFace, IBM, and Microsoft Research as well as institutions like the Allen Institute, Stanford, the Tokyo Institute of Technology, and the University of Munich.
Features#
- Advanced web crawling and text discovery:
Support for sitemaps (TXT, XML) and feeds (ATOM, JSON, RSS)
Smart crawling and URL management (filtering and deduplication)
- Parallel processing of online and offline input:
Live URLs, efficient and polite processing of download queues
Previously downloaded HTML files and parsed HTML trees
- Robust and configurable extraction of key elements:
Main text (common patterns and generic algorithms like jusText and readability)
Metadata (title, author, date, site name, categories and tags)
Formatting and structure: paragraphs, titles, lists, quotes, code, line breaks, in-line text formatting
Optional elements: comments, links, images, tables
- Multiple output formats:
TXT and Markdown
CSV
JSON
HTML, XML and XML-TEI
- Optional add-ons:
Language detection on extracted content
Speed optimizations
- Actively maintained with support from the open-source community:
Regular updates, feature additions, and optimizations
Comprehensive documentation
Evaluation and alternatives#
Trafilatura consistently outperforms other open-source libraries in text extraction benchmarks, showcasing its efficiency and accuracy in extracting web content. The extractor tries to strike a balance between limiting noise and including all valid parts.
The benchmark section details alternatives and results, the evaluation readme describes how to reproduce the evaluation.
In a nutshell#
Primary installation method is with a Python package manager: pip install trafilatura (→ installation documentation).
With Python:
>>> import trafilatura
>>> downloaded = trafilatura.fetch_url('https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/')
>>> trafilatura.extract(downloaded)
# outputs main content and comments as plain text ...
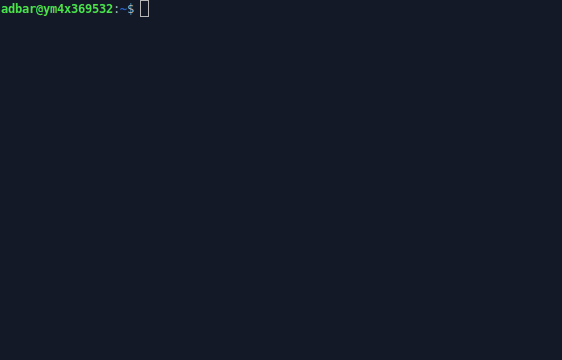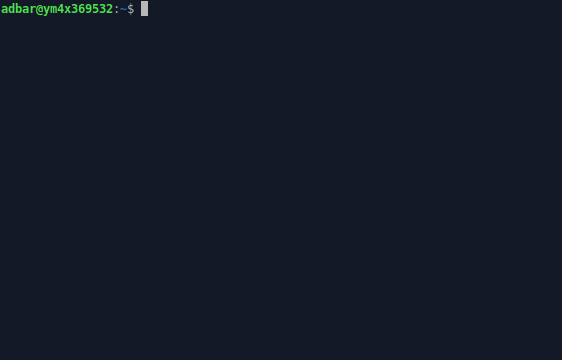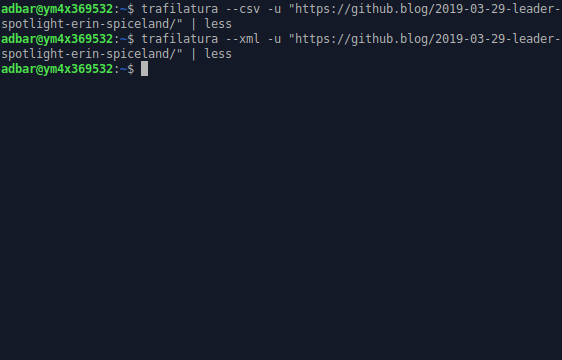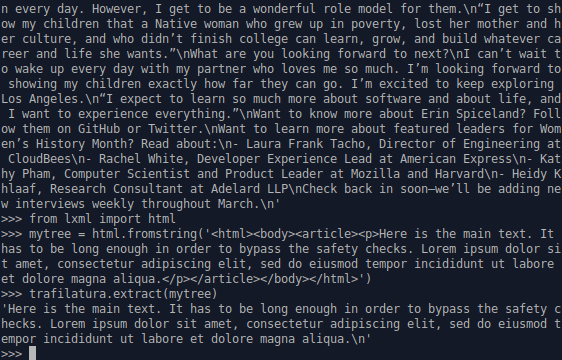
On the command-line:
$ trafilatura -u "https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/"
# outputs main content and comments as plain text ...
For more see usage documentation and tutorials.
License#
This package is distributed under the Apache 2.0 license.
Versions prior to v1.8.0 are under GPLv3+ license.
Context#
This work started as a PhD project at the crossroads of linguistics and NLP, this expertise has been instrumental in shaping Trafilatura over the years. Initially launched to create text databases for research purposes at the Berlin-Brandenburg Academy of Sciences (DWDS and ZDL units), this package continues to be maintained but its future depends on community support.
If you value this software or depend on it for your product, consider sponsoring it and contributing to its codebase. Your support on GitHub or ko-fi.com will help maintain and enhance this popular package. Visit the Contributing page for more information.
Trafilatura is an Italian word for wire drawing symbolizing the refinement and conversion process. It is also the way shapes of pasta are formed.
Citing Trafilatura#
Trafilatura is widely used in the academic domain, chiefly for data acquisition. Here is how to cite it:
@inproceedings{barbaresi-2021-trafilatura,
title = {{Trafilatura: A Web Scraping Library and Command-Line Tool for Text Discovery and Extraction}},
author = "Barbaresi, Adrien",
booktitle = "Proceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
pages = "122--131",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-demo.15",
year = 2021,
}
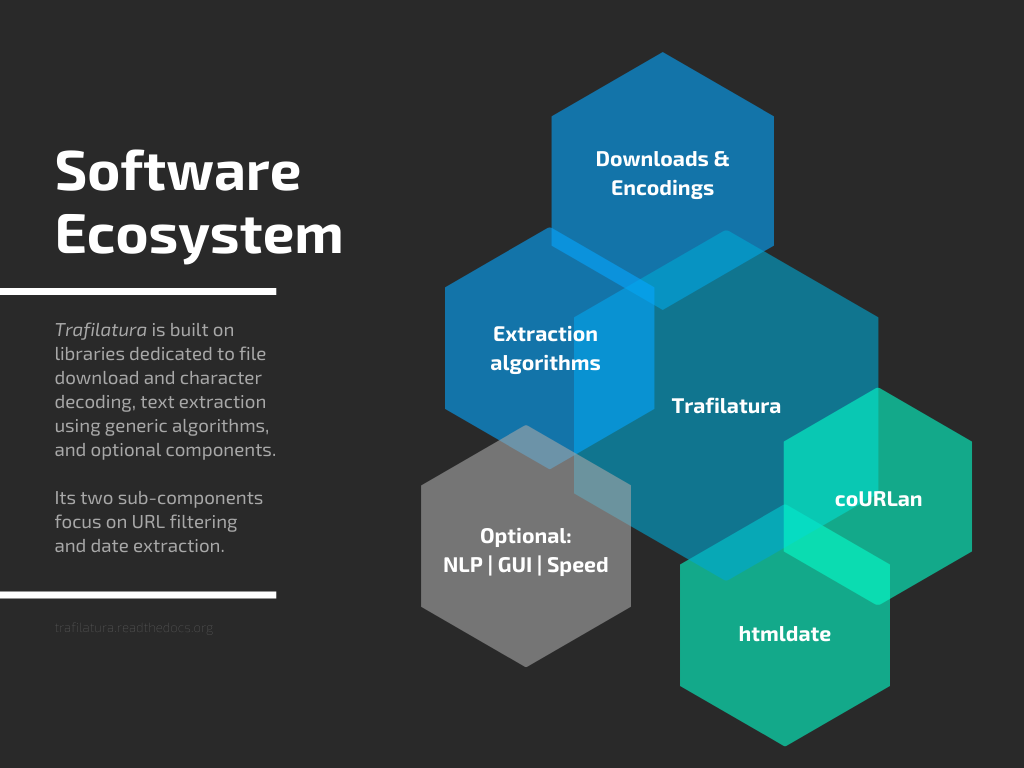
Software ecosystem#
Jointly developed plugins and additional packages also contribute to the field of web data extraction and analysis:
Corresponding posts can be found on Bits of Language. The blog covers a range of topics from technical how-tos, updates on new features, to discussions on text mining challenges and solutions.
Building the docs#
Starting from the docs/ folder of the repository:
pip install -r requirements.txtsphinx-build -b html . _build/(where_buildis the target directory)
Changes#
For version history and changes see the changelog.