Tutorial: DWDS-Korpusdaten reproduzieren#
Ziel#
Die Korpusdaten des Digitalen Wörterbuchs der deutschen Sprache sind mithilfe eines externen Tools reproduzierbar. Anhand dieser Anleitung können Sie Daten unabhängig vom DWDS-Projekt selbst zusammenstellen, speichern und verwalten. Die dafür benötigten Tools sind frei verfügbar und erfordern keine fortgeschrittenen IT-Kenntnisse.
Das grundsätzliche Problem besteht darin, dass die Originalsammlung selbst nicht uneingeschränkt kopiert und weitergegeben werden darf. Die Nutzung des DWDS-Portals als Suchmaschine ist aber möglich, ebenso wie das Tätigen eigenhändiger Downloads, um die Sammlung zu replizieren. Auf diesem Wege muss kein Zugang zu den Rohdaten gewährt und keine unmittelbare Kopie erzeugt werden.
Von einer Abfrage zur Einsicht der Quellen#
Note
Um die meisten Webkorpora des DWDS online abfragen zu können, ist eine kostenlose Anmeldung notwendig: Jede/r kann sich beim DWDS-Portal registrieren oder anmelden.
Ergebnisse zur weiteren Nutzung exportieren#
Mithilfe der Export-Funktion können Links aus den Trefferlisten zur Basis eines eigenen Korpus oder Subkorpus werden.
In jedem DWDS-Korpus können Sie die Ergebnisse einer Abfrage exportieren. So können Trefferlisten aus der DWDS-Plattform weiter bearbeitet und ausgewertet werden. Wenn Sie auf den blauen Knopf „Treffer exportieren“ klicken, haben Sie die Wahl zwischen mehreren Formaten.
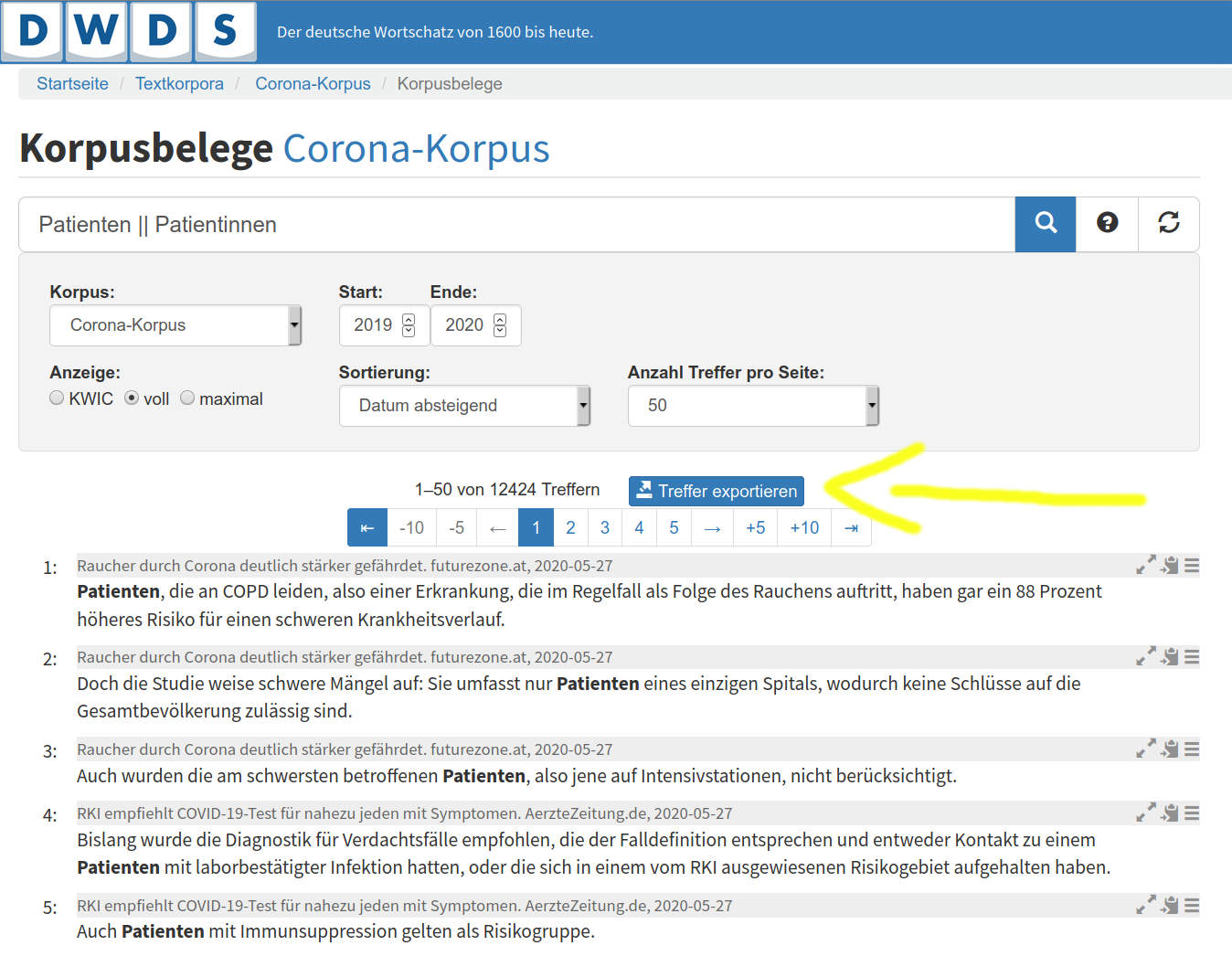
Trefferliste im DWDS-Portal und Knopf „Treffer exportieren“#
CSV- oder TSV-Dateien können von der frei verfügbaren Software LibreOffice Calc sowie von Microsoft Excel oder Apple Numbers geöffnet werden. Die Quellen (URLs) werden in einer Spalte aufgelistet und können dann als getrennte Liste anderswo gespeichert werden.
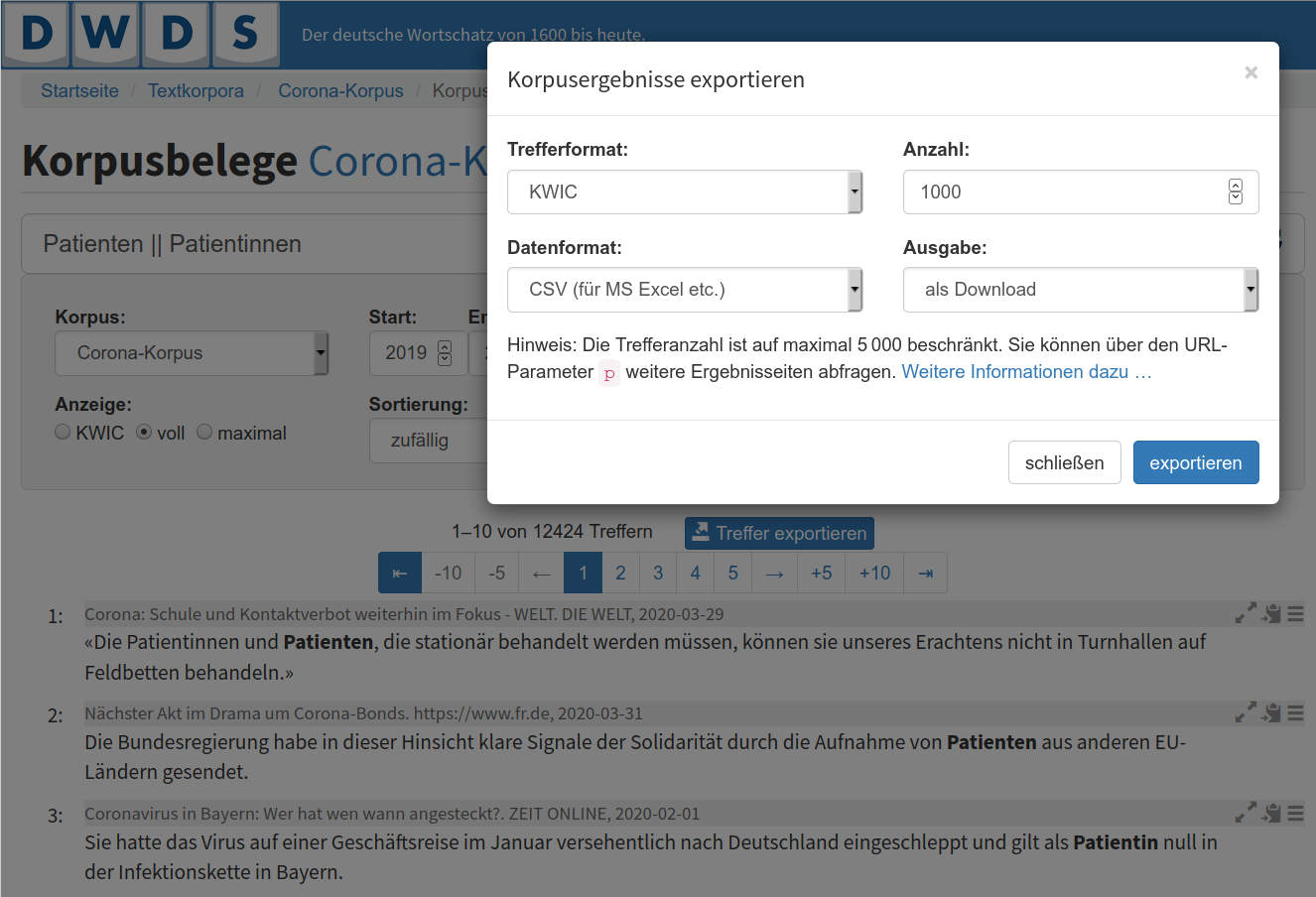
Kontextmenü „Treffer exportieren“ und Wahl des Ausgabeformats#
Von einem Webkorpus zu URL-Listen#
Alternativ können Sie mit dieser besonderen Art der Abfrage URLs in gebündelter Form im TSV-Format exportieren. Damit kommen Sie zu einer Liste von Quellen, die zur weiteren Nutzung auch heruntergeladen werden kann.
In dieser Form gilt das nur für Webkorpora. Im Übrigen ist es auch möglich, Informationen aus unterschiedlichen Metadatenfeldern zu zählen, siehe die entsprechende Dokuseite.
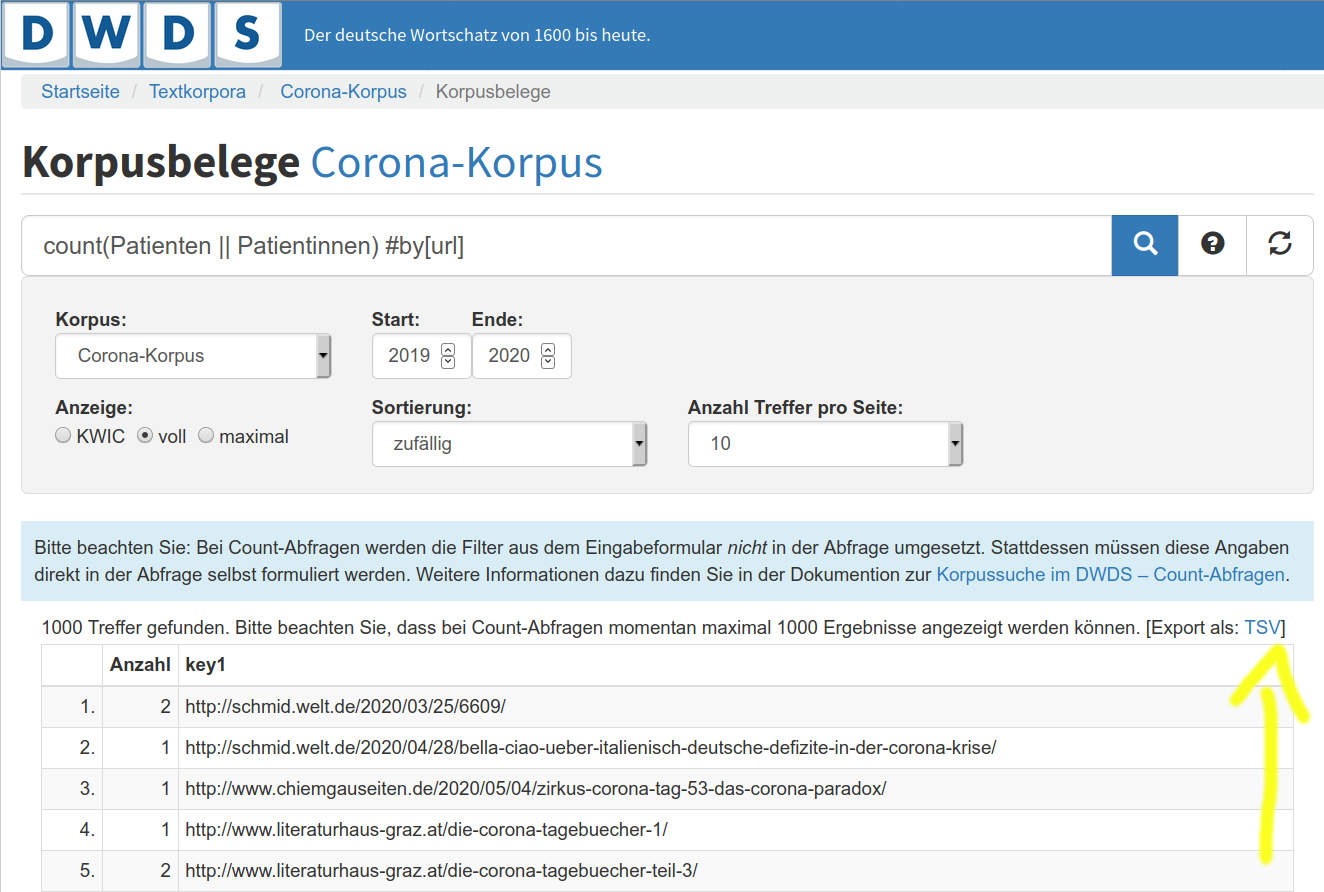
Trefferliste nach Quelle sortiert#
Nachdem Sie die CSV- oder TSV-Datei mit der Tabellenkalkulationssoftware Ihrer Wahl geöffnet haben, können Sie die URL-Spalte auswählen und in einer TXT-Datei kopieren, die Sie als Eingabe für Trafilatura verwenden werden (siehe unten).
Interesse und Gestaltungsmöglichkeiten#
Anhand von solchen URL-Listen haben Sie zwei Möglichkeiten, Sie können:
Korpusdaten reproduzieren, sofern die Seiten noch verfügbar oder in Archiven zu finden sind;
Ein maßgeschneidertes Korpus auf der Basis einer DWDS-Abfrage zusammenstellen.
So wird die DWDS-Plattform zu einer Art Meta-Suchmaschine. Der Vorteil besteht darin, dass Sie nicht von dem wilden Web abhängig sind, sondern in allgemeinen oder thematischen Sammlungen suchen, die hinsichtlich ihrer Relevanz geprüft worden sind. Außerdem wird die Datenmenge dadurch übersichtlicher.
Hint
Hier finden Sie eine Liste der Webkorpora auf der DWDS-Plattform.
Bei größeren Webkorpora ist die Filterung hinsichtlich der Relevanz und der Textqualität meistens quantitativer Natur, siehe Barbaresi 2015 (Diss.) Kapitel 4 für Details. Im Übrigen haben wir das Schlimmste aus dem Web manuell ausgegrenzt.
Download und Verarbeitung der Daten#
Für die eigenhändige Zusammenstellung von Korpusdaten brauchen Sie:
Grundkenntnisse im Umgang mit Python, R oder der Kommandozeile (siehe Hinweise zur Nutzung der Kommandozeile oder diese Einführung in die Kommandozeile auf Deutsch);
Eine aktuelle Version der Software Trafilatura, siehe Installation.
Im Grunde geben Sie Links (URLs) in der Form einer Liste ein und erhalten als Ausgabe eine Reihe von Dateien als TXT, CSV oder XML. Für weitere Informationen können Sie die folgende Anleitung sowie diese Dokumentationsseiten auf Englisch lesen:
Download und Verarbeitung mit Python, R, auf der Kommandozeile oder mit einer graphischen Oberfläche.
Mehrfach vorhandene URLs in der Eingabeliste werden automatisch dedupliziert und die Reihenfolge der Downloads wird optimiert, Sie müssen diese Schritte also nicht selber durchführen.
Falls sich die betroffenen Webseiten in der Zeit zwischen der DWDS-Archivierung und Ihrem Download nicht geändert haben, erhalten Sie genau die gleichen Daten. Alternativ können Sie eine archivierte Version der Seiten verwenden, sofern sie in Internet Archiven zu finden sind.
Beispiel: Wie kann man die Seiten herunterladen, speichern und konvertieren?#
Hier ist eine Empfehlung für die Kommandozeile, die eine Datei namens linkliste.txt liest (eine URL pro Zeile).
Diese Linkliste kann zunächst gefiltert werden, um deutschsprachige, inhaltsreiche Webseiten zu bevorzugen. Der dafür nötige Softwareteil, courlan wird mit Trafilatura installiert:
courlan --language de --strict --inputfile linkliste-roh.txt --outputfile linkliste-gefiltert.txt
Die Ausgabe von Trafilatura erfolgt auf zweierlei Weise: die extrahierten Texte (TXT-Format) im Verzeichnis ausgabe und eine Kopie der heruntergeladenen Webseiten unter html-quellen (zur Archivierung und ggf. erneuten Verarbeitung):
trafilatura --input-file linkliste.txt --output-dir ausgabe/ --backup-dir html-quellen/
So werden TXT-Dateien ohne Metadaten ausgegeben. Wenn Sie --csv, --json, --xml oder --xmltei hinzufügen, werden Metadaten einbezogen und das entsprechende Format für die Ausgabe bestimmt. Zusätzliche Optionen sind verfügbar, siehe die passenden Dokumentationsseiten.
Für bis zu einige Tausend URLs gelingt dieses Verfahren problemlos von einem Laptop aus, für mehr URLs kann ein Server notwendig sein, vor allem um lange Wartezeiten zu handhaben (zunächst werden die Seiten nämlich heruntergeladen).